
Veille informative automatique via scraping de flux RSS
Se tenir informer est un enjeu crucial à notre époque. Avec la multitude de sources d'information et la rapidité d'évolution des technologies, il est facile de passer à côté d'une nouveauté importante. Chacun à sa propre stratégie concernant la veille informative. Pour ma part, j'ai souhaité automatisé de manière hebdomadaire la récupération des articles des différents sites ou réseaux sociaux que je suis activement, en complément de ma veille active au quotidien. On retrouve beaucoup de solutions à base d'automatisation no-code ou low-code, mais je ne retrouvais pas la souplesse et la finesse que je recherche dans ce genre d'outil, c'est pourquoi j'ai voulu concevoir mon propre programme.
Récupération des données
Dans un premier temps, le programme récupère les derniers articles des différents flux RSS qui ont été saisis dans le fichier de configuration (il ne s'agit que d'une simple liste facile à modifier sur la durée). Le programme récupère ainsi les derniers articles des 7 derniers jours. le titre de l'article, sa date de publication et son URL sont récupérés par la même occasion grâce au package feedparser.
Pour que la veille soit efficace, il est souhaitable d'avoir un petit résumé court et journalistique associé à l'article, afin de pouvoir savoir rapidement s'il sera intéressant ou non. Pour cela, le programme va scraper les articles à partir de l'URL récupérée précédemment. Le scraping des articles est ainsi rendu possible grâce aux packages requests et BeautifulSoup.
Résumé et reporting
Les données ainsi scrapées et agrégées des différents articles nécessitent alors une phase de nettoyage pour être pleinement exploitées, notamment en retirant les différentes balises HTML non nécessaires issues du scraping. Suite à cela, le programme utilise un modèle de langage open-source spécialisé dans les courts résumés journalistiques (facebook/bart-large-cnn) disponible sur Hugging-Face via le package transformers (de plus, il fonctionne particulièrement bien pour les articles en français comme en anglais). Ainsi, les données agrégées maintenant propres sont passées au modèle qui va, pour chaque article, réaliser un court résumé d'environ 60-100 mots.
Maintenant que tous les éléments sont propres et formatés pour chaque article, les éléments sont mis en forme selon un modèle Markdown. Une fois chaque article traité, le document Markdown est exporté afin d'avoir une trace du contenu créé suite à la veille informative.
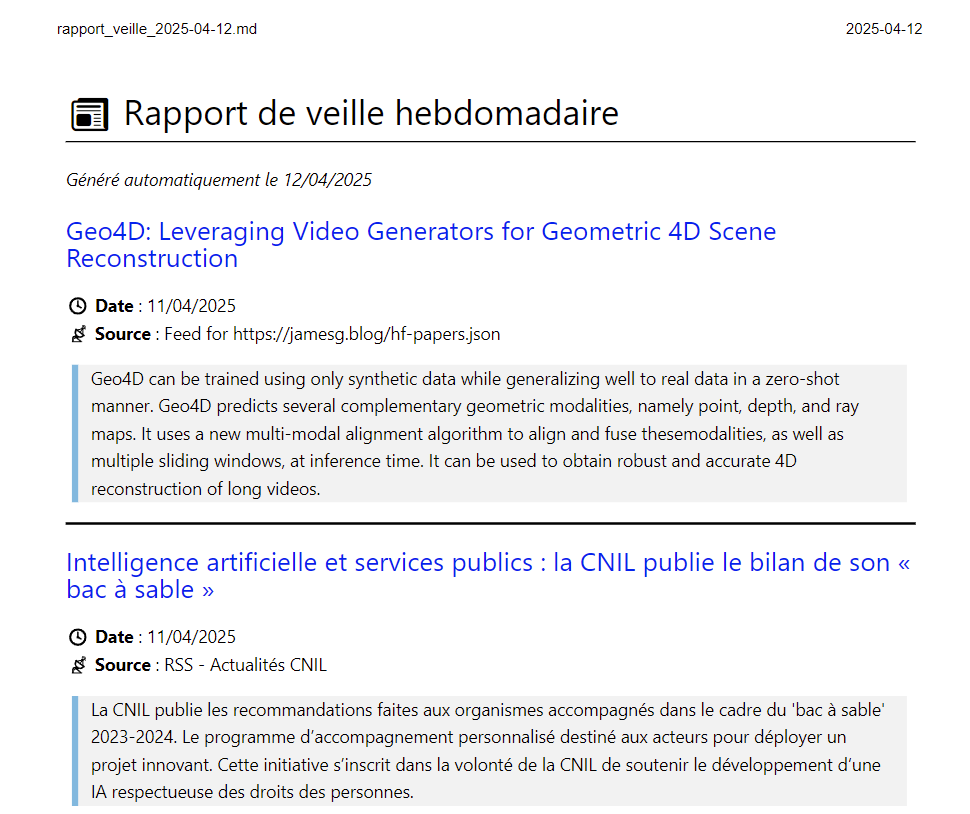
Rendu final du rapport de veille
Envoi hebdomadaire
Le programme pourrait s'arrêter là, avec un rapport clair et standard issu des 7 derniers jours d'information. Cependant, l'idéal serait d'avoir cette veille qui se réalise automatiquement chaque semaine pour ensuite envoyer le rapport sur sa boite mail avant 8h par exemple.
Dans un premier temps, il convient de bien paramétrer son adresse mail et la configuration des paramètres SMTP (Server et Port) afin d'officialiser le lien entre l'adresse mail et le programme. Pour certaines plateformes comme Gmail, il peut être nécessaire de générer un token applicatif pour autoriser l'accès. Tout ceci est assez simple à l'aide du pacage smtplib de Python.
Suite à cela, il suffit simplement de déployer ce programme sur un service Cloud comme GitHub, Databricks, AWS voire même son propre NAS via une image Docker (c'est cette dernière option que j'ai personnellement choisie). Une fois déployé, un petit cronjob pour lancer le programme chaque mardi à 6h et le rapport arrive bien au chaud dans sa boite mail chaque semaine, faisant économiser beaucoup de temps pôur optimiser sa veille informative !
En raison du nombre important d'étapes critiques, le programme enregistre chaque étape dans un fichier log pour retracer les évènements de manière claire. De plus, toutes les données importantes sont stockées dans un fichier .env pour assurer une protection supplémentaire.
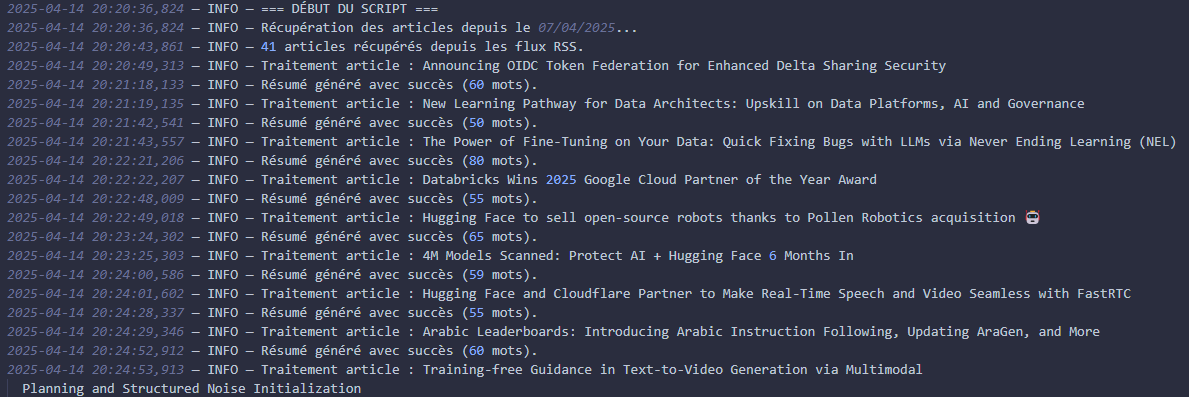
Exrtait du début du logger
Conclusion
Ce projet est un exemple typique d'automatisation d'une tâche répétitive à l'aide d'outils appropriés, sans partir dans l'excès de modèles disproportionnés et tout en gardant une souplesse et une personnalisation propre aux désirs de chacun.
Ce projet fait appel à une logique de collecte, de nettoyage, de scraping de données, de formatage et de reporting automatisé.