
Chatbot RAG Langchain pour l'exploration de PDF
La puissance de l'IA permet d'apporter un soutien considérable dans l'exploration de la bibliographie. Lorsque l'on commence à avoir une collection très étoffée, il peut être très éprouvant de rechercher une information. Ce projet vise à fournir un assistant virtuel capable d'explorer et d'extraire des informations à partir de documents PDF en utilisant un chatbot intégré avec la technologie RAG (Retrieval-Augmented Generation). Le chatbot répond aux questions de l'utilisateur en s'appuyant sur un VectorStore créé à partir des documents PDF chargés, tout en utilisant un modèle de langage de Hugging Face pour générer des réponses.
Processing des données
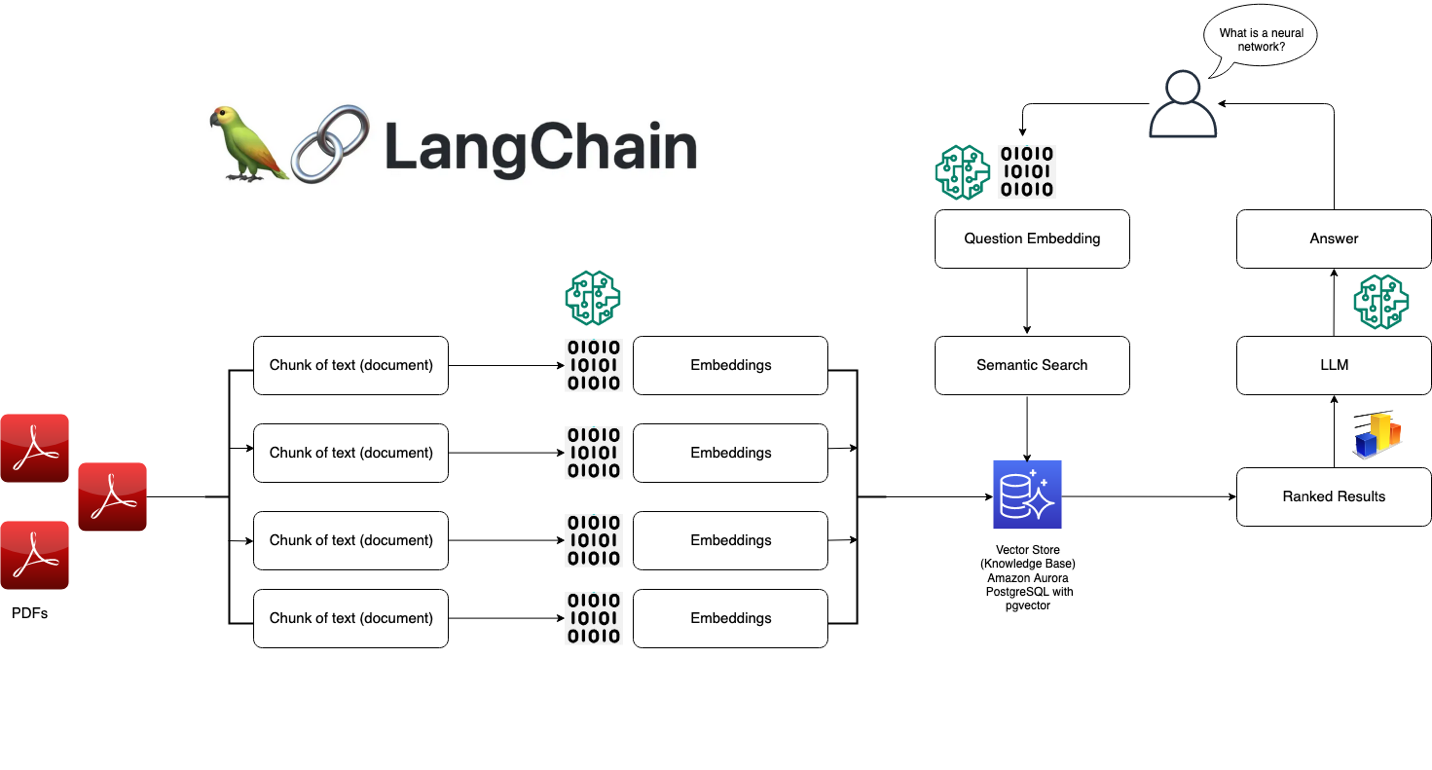
La première étape de ce projet consiste à charger et transformer les documents en inputs en un format standard et exploitable pour l'IA. De ce fait, les documents *.pdf sont récupérés depuis le répertoire spécifié /data à l'aide de Langchain. Elle permet d'extraire tous les fichiers *.pdf présents dans le dossier puis le contenu est ensuite chargé dans une liste de documents.
Une fois tous les documents extraits, le texte doit être découpé en morceaux de taille appropriée pour pouvoir garder le contexte des informations. Le texte est segmenté en morceaux de 500 caractères avec un chevauchement de 50 caractères pour garantir des informations cohérentes et pertinentes. On peut imaginer jouer sur ces valeurs pour gagner en robustesse au détriment de la mémoire.
Une fois ces étapes réalisées, le texte doit être transformé en un format compréhensible pour les modèles LLM. Chaque morceau de texte est alors converti en un embedding via le modèle pré-entrainé sentence-transformers/all-MiniLM-L6-v2 de Hugging-Face. Cela permet de représenter chaque document par un vecteur de caractéristiques dans un espace multidimensionnel.
Enfin, les embeddings sont stockés dans un VectoreStore (via FAISS), qui est une structure de données permettant une recherche rapide et efficace dans de grands ensembles de documents. Le VectorStore est ensuite suavegardé localement pour poivoir être réutilisé sans avoir à recomposer l'ensemble des embeddings à chaque fois.
Data Flow Diagram du raisonnement du projet
Interaction et réponse
Maintenant que les données sont exploitables, le projet peut déjà être utilisé comme tel. Cependant, il est plus confortable de pouvoir intéragir avec le modèle à travers une interface graphique interactive basique. Une UI est donc réalisée avec Streamlit permettant à l'utilisateur de poser des questions via un champ de saisie interactif. Les messages échangés sont stockés temporairement dans la session en cours pour maintenir une mémoire à la conversation. Aucun donnée n'est cependant conservée de manière durable et l'historique disparait à l'arrêt de l'application.
Une fois les données pertinentes récupérées du VectoreStore, le modèle LLM mistralai/Mistral-7B-Instruct-v0.3 est chargé depuis Hugging-Face via son endpoint afin de construire une réponse contextuelle et naturelle aux questionnements de l'utilisateur à partir des données des *.pdf.
Lorsqu'une question est posée, un processus de Retrieval-based Question Answering (QA) est déclenché, c'est-à-dire que le modèle va chercher les informations pertinentes dans le VectoreStore en interrogeant les documents via leur représentation en embeddings. Un PromptTemplate personnalisé est utilisé pour cadrer la requête de manière efficace et pour répondre en détaillant les points importants extraits du contexte disponible.
Une fois la réponse générée, elle est affichée dans l'interface utilisateur, accompagnée des sources extraites (les fichiers *.pdf) et des pages spécifiques où l'information a été trouvée. Cela permet de donner un maxium de transparence à l'utilisateur concernant l'origine des réponses fournies.
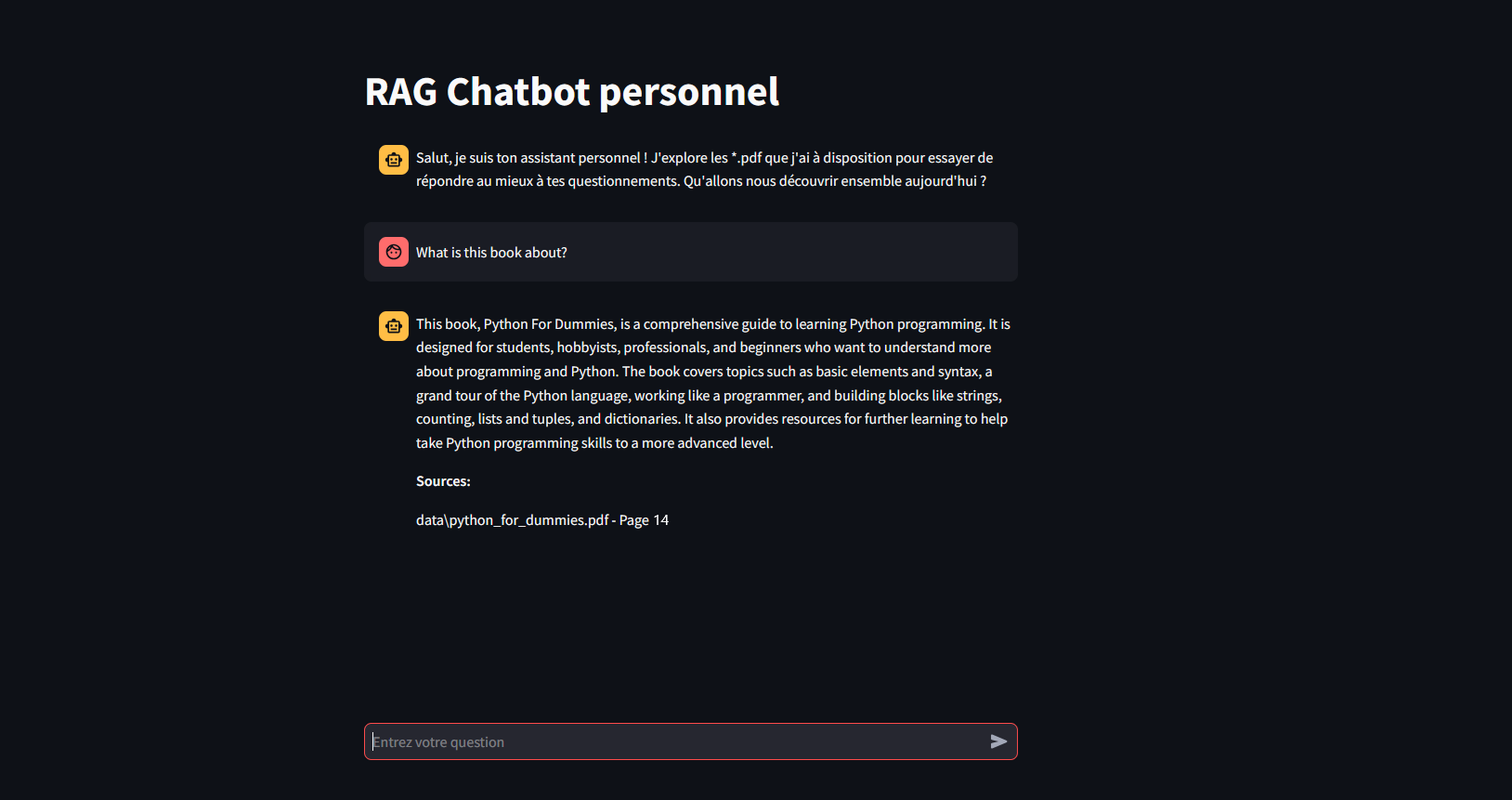
Interface simple du Chatbot sur Streamlit
Conclusion
Ce projet utilise une approche hybride de récupération d'information et de génération de texte pour fournir une expérience utilisateur interactive et intelligente. Grâce à l'intégration de technologies comme Langchain, Hugging Face, et FAISS, il est capable de traiter de grands volumes de données PDF et de répondre de manière précise et détaillée aux questions des utilisateurs, tout en offrant une transparence sur les sources utilisées.
Du fait de l'utilisation de petits modèles, l'application est performante surtout en anglais. Il suffit de passer sur des modèles multilangues plus puissants pour améliorer la qualité des réponses dans d'autres langues.