
Prédiction du churn client en entreprise
Le churn client est défini comme le moment où les clients ou les abonnés cessent de faire affaire avec une entreprise ou un service. Si une entreprise pouvait prédire quels clients sont susceptibles de partir à l'avance, elle pourrait concentrer ses efforts de rétention des clients uniquement sur ces clients "à haut risque". L'objectif ultime est d'étendre sa zone de couverture et de récupérer plus de fidélité des clients. La clé du succès dans ce marché réside dans le client lui-même.
Processing et modélisation
Dans un premier temps, sur ce genre de problématique, il est important de comprendre la distribution des clients qui restent et qui partent pour s'imprégner d'une potentielle logique. Les pourcentages de clients retenus et de clients ayant churné sont calculés et affichés. Des histogrammes sont également tracés pour visualiser les distributions des caractéristiques numériques telles que la durée de l'abonnement tenure et les charges mensuelles MonthlyCHarges.
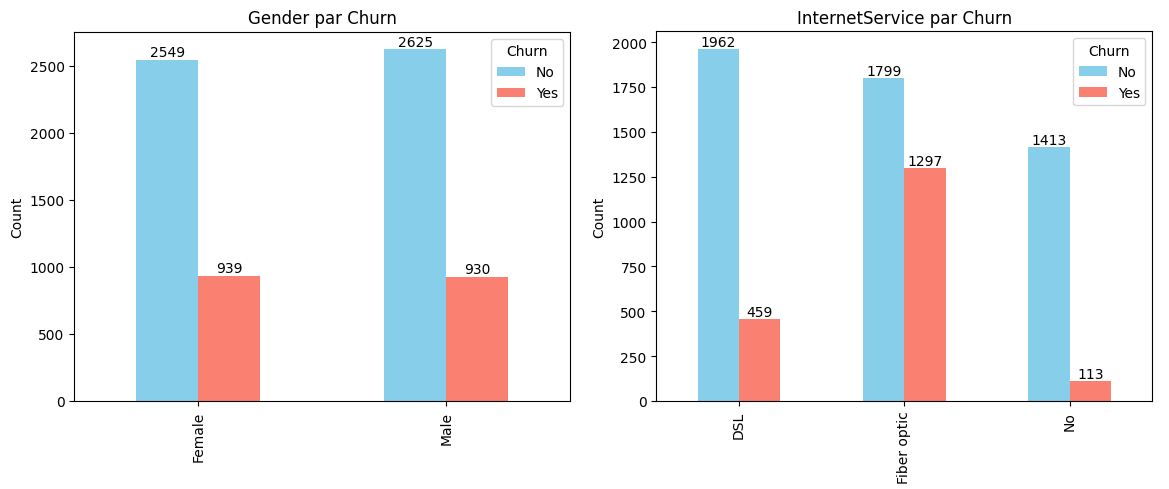
Histogrammes du Churn en fonction du genre et du service internet utilisé
Pour préparer les données à l'analyse, les identifiants des clients sont supprimés pour anonymiser les données. Ensuite, un LabelEncoder est appliqué sur les variables non numériques pour les convertir en valeurs numériques. Une matrice de corrélation est également calculée et visualisée pour comprendre les relations entre les différentes variables.
Comme les données traitées sont des données confidentielles, il est indispensable de les anonymiser afin de garder toute objectivité et de sécuriser leur utilisation. De cette manière, toutes les informations nominatives non pertinentes sont supprimées.
Pour normaliser les données, un StandardScaler est appliqué sur les caractéristiques. Les ensembles de données sont ensuite divisés en ensembles d'entraînement et de test en utilisant train_test_split.
Comme le Machine Learning est une science itérative, il est important de tester plusieurs solutions pour comparer les résultats. Ainsi, plusieurs modèles de classification sont initialisés et entraînés, notamment la régression logistique (LogisticRegression), les k-plus proches voisins (KNeighborsClassifier), les machines à vecteurs de support (SVC), et les forêts aléatoires (RandomForestClassifier). Chaque modèle est entraîné sur les données d'entraînement et des prédictions sont faites sur les données de test.
Optimisation du modèle
Classiquement, l'optimisation des hyperparamètres du modèle de régression logistique est opérée via une grille de paramètres définie et une recherche par grille (GridSearchCV). Les meilleurs paramètres trouvés sont affichés et le modèle optimisé est évalué sur les données de test. Le meilleur modèle offre une précision de 0.81, ce qui est particulièrement satisfaisant pour ce genre de contexte d'étude.
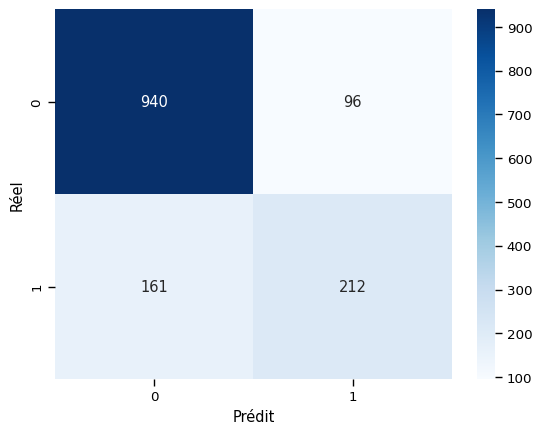
Matrice de confusion du meilleur modèle de LinearRegression
Conclusion
Cette étude de cas montre comment les techniques de Machine Learning peuvent être appliquées pour prédire le churn client. Ensuite, l'utilisation de GridSearchCV permet d'optimiser les hyperparamètres du modèle, améliorant ainsi sa performance. L'évaluation rigoureuse du modèle à l'aide de diverses métriques et d'une matrice de confusion assure une compréhension complète de ses performances. Enfin, il est noté que la méthode utilisée peut être généralisée à d'autres types de données de churn ou à d'autres secteurs, offrant ainsi une approche flexible et robuste.