
Diagnostic automatique à partir de radiographies pulmonaires COVID-19
Dans le cadre d'une de mes formations, j'ai pu réaliser, en groupe, un projet de Computer Vision utilisant un jeu de données >20k de radiographies pulmonaires brutes afin d'identifier trois pathologies (dont le COVID) ainsi que les patients sains. Pour ce faire, j'ai réalisé un nettoyage complet des images grâce à une fonction personnalisée permettant de générer de la standardisation dans les tests puis automatiser les transformations nécessaires. Une fois l'étape de data cleaning réalisée, le data processing a consisté à normaliser les images et de les redimensionner pour qu'elles correspondent toutes au format du jeu d'entrainement. Ensuite, en partant d'un modèle baseline simple, divers tests de GridSearching a permis de déterminer les paramètres optimaux. Ensuite, nous nous sommes partagés une dizaine de modèles existants pour réaliser du fine-tuning sur nos données d'entrainement en utilisant la puissance computationnelle des GPU. Au final, notre projet s'est arrêté sur deux modèles aux résultats prometteurs : DenseNet et VGG16. En effet, dans la limite des deux mois qui nous a été imposée, nous avons réussi à obtenir 0.96 de précision et de F1-Score sur la pathologie COVID, et plus de 0.91 sur les autres catégories.
Logique du projet
La radiographie est une technique d'imagerie médicale couramment utilisée pour visualiser les structures internes du corps. En particulier, les radiographies pulmonaires sont essentielles pour le diagnostic et la surveillance de diverses pathologies, y compris la COVID-19. Cette maladie, causée par le coronavirus SARS-CoV-2, peut induire des anomalies spécifiques dans les poumons visibles sur les radiographies, telles que les opacités en verre dépoli. Face à la pandémie mondiale, il était crucial de disposer d'outils permettant un diagnostic rapide et précis pour améliorer la prise en charge des patients.

Echantillon de radiographies du dataset
La première étape a été de préparer un dataset de 21 165 radiographies et masques issus de plusieurs sources. Ce travail préliminaire comprenait l'exploration des métadonnées, la normalisation des images, et leur redimensionnement pour uniformiser les entrées pour les modèles de convolution (CNN).
Après avoir sélectionné les modèles les plus performants lors des phases de benchmarking, nous avons procédé à des ajustements fins (fine-tuning). Ceci a inclus le dégèlement de couches spécifiques des modèles préentraînés et l'optimisation des hyperparamètres pour maximiser la précision et le F1 Score sur nos données de validation.
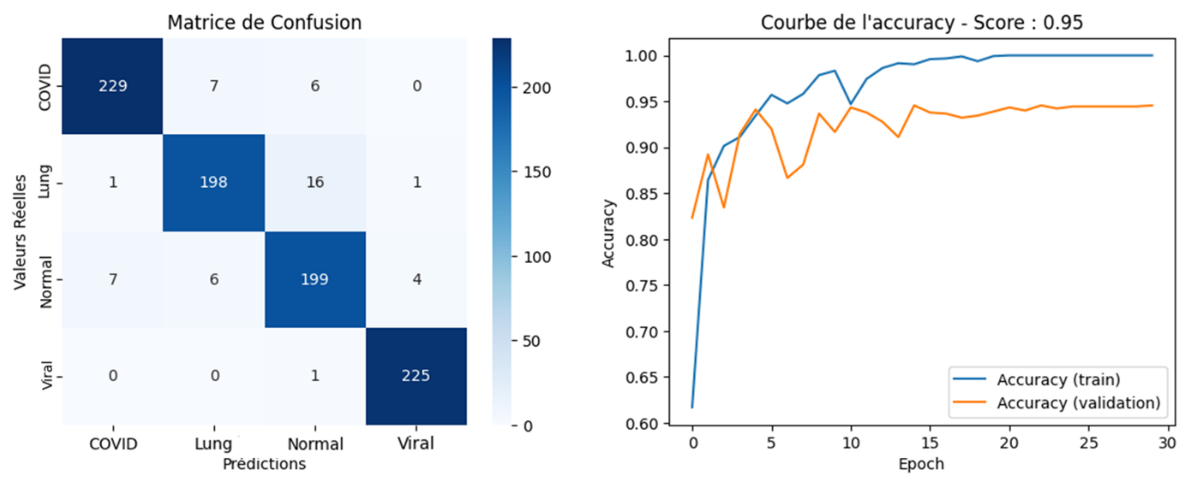
Matrice de confusion du modèle VGG16 finetuned et courbes d’apprentissage sur l’ensemble de validation
Les modèles finaux ont été évalués en termes de précision, sensibilité, spécificité, et d'autres métriques cliniquement pertinentes. L'interprétabilité des résultats a été améliorée grâce à des techniques comme les GRAD-CAM et l'analyse des caractéristiques les plus importantes influençant les prédictions des modèles.
Process d'optimisation
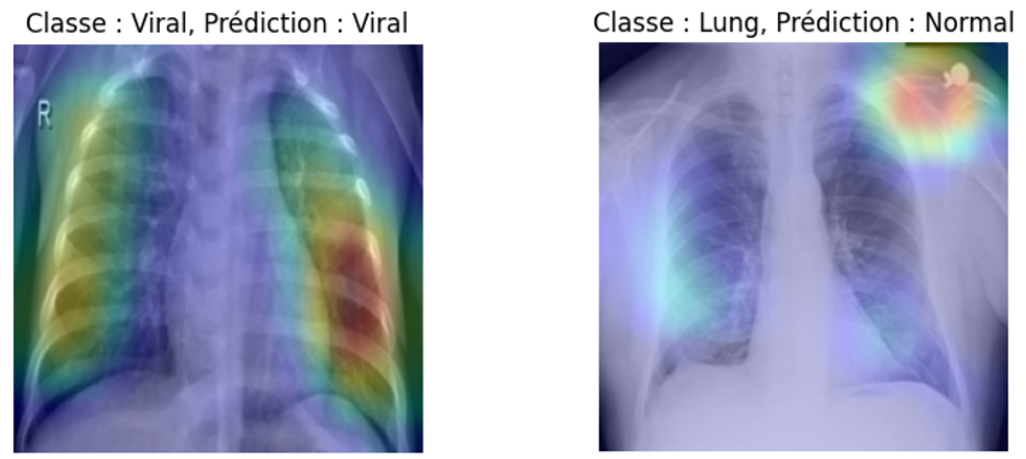
Illustration par GRAD-CAM des zones pertinentes ayant été exploitées par le réseau de neurones pour donner la prédiction
Sur la prédiction réussie (image de gauche), il est intéressant de constater que le modèle s’est largement appuyé sur une vision des poumons. Il est aussi constatable que sa vision semble avoir été un peu influencée par l’annotation ‘R’ présente sur la radiographie. Ceci est d’autant plus visible sur la prédiction faussée (image de droite), où le modèle a tout de même pris des informations sur les poumons, mais s’est surtout concentré sur un artefact présent sur l’épaule gauche du patient.
Le modèle VGG16 ajusté a atteint une précision de validation et un F1 Score impressionnants de 0.96 pour la détection de la COVID-19, et de 0.91 pour les cas normaux. Ces résultats démontrent l'efficacité des approches de Deep Learning dans le domaine de l'imagerie médicale et leur potentiel pour améliorer le diagnostic rapide et précis des pathologies pulmonaires. Le modèle a été déployé via une application web Streamlit afin de permettre une utilisation simple et intuitive.
Cependant, aucun modèle n’est parfait et il est toujours possible de pousser les performances plus loin. En effet, il serait possible d’enrichir le dataset par des techniques d’augmentation de données pour améliorer la robustesse du modèle à des variations non vues pendant l’entraînement, par exemple. De plus, approfondir l’optimisation des hyperparamètres pour maximiser les performances est toujours possible tout en explorant des architectures hybrides qui combinent les points forts de plusieurs modèles pré-entraînés pour améliorer la généralisation.
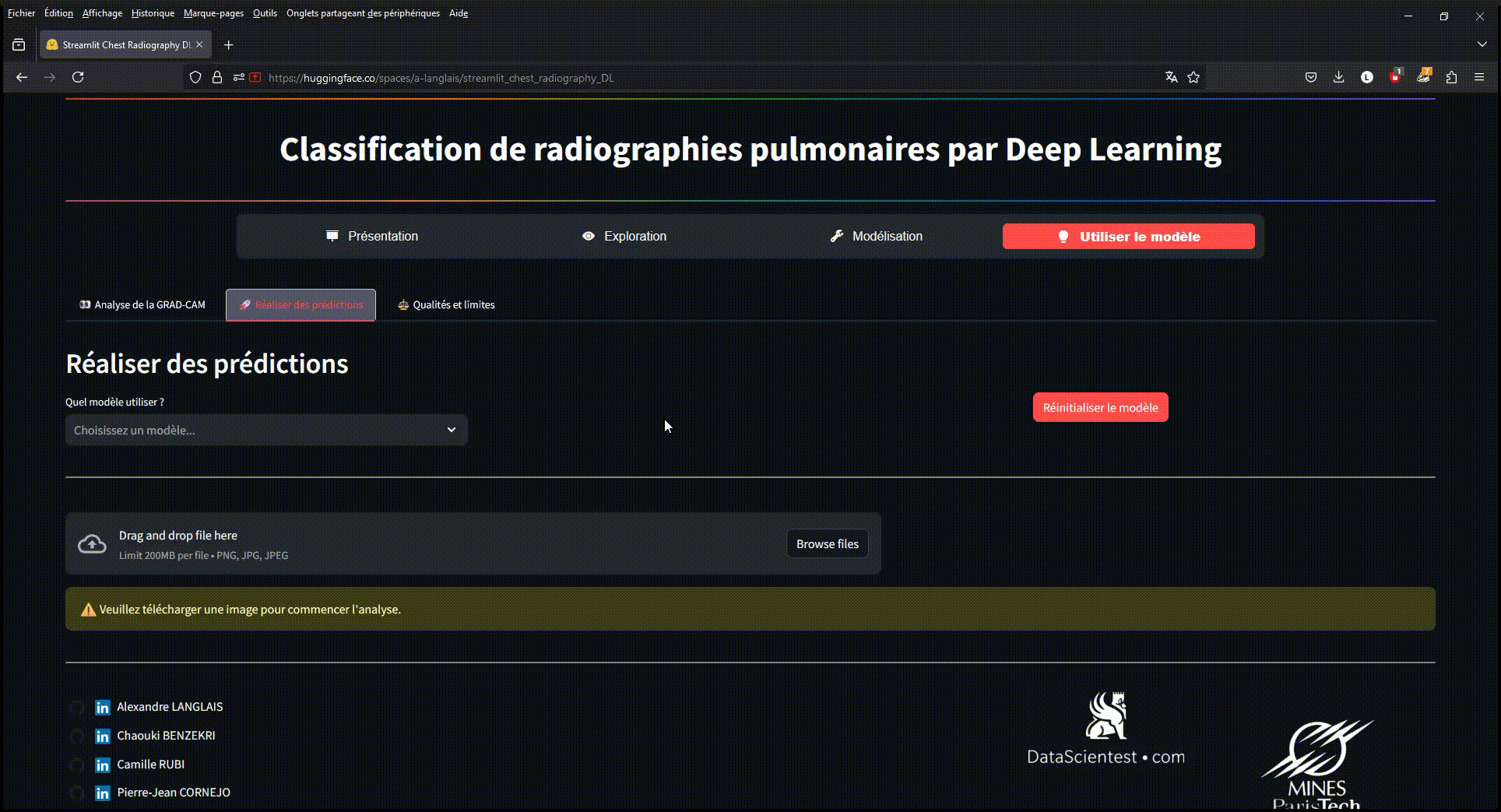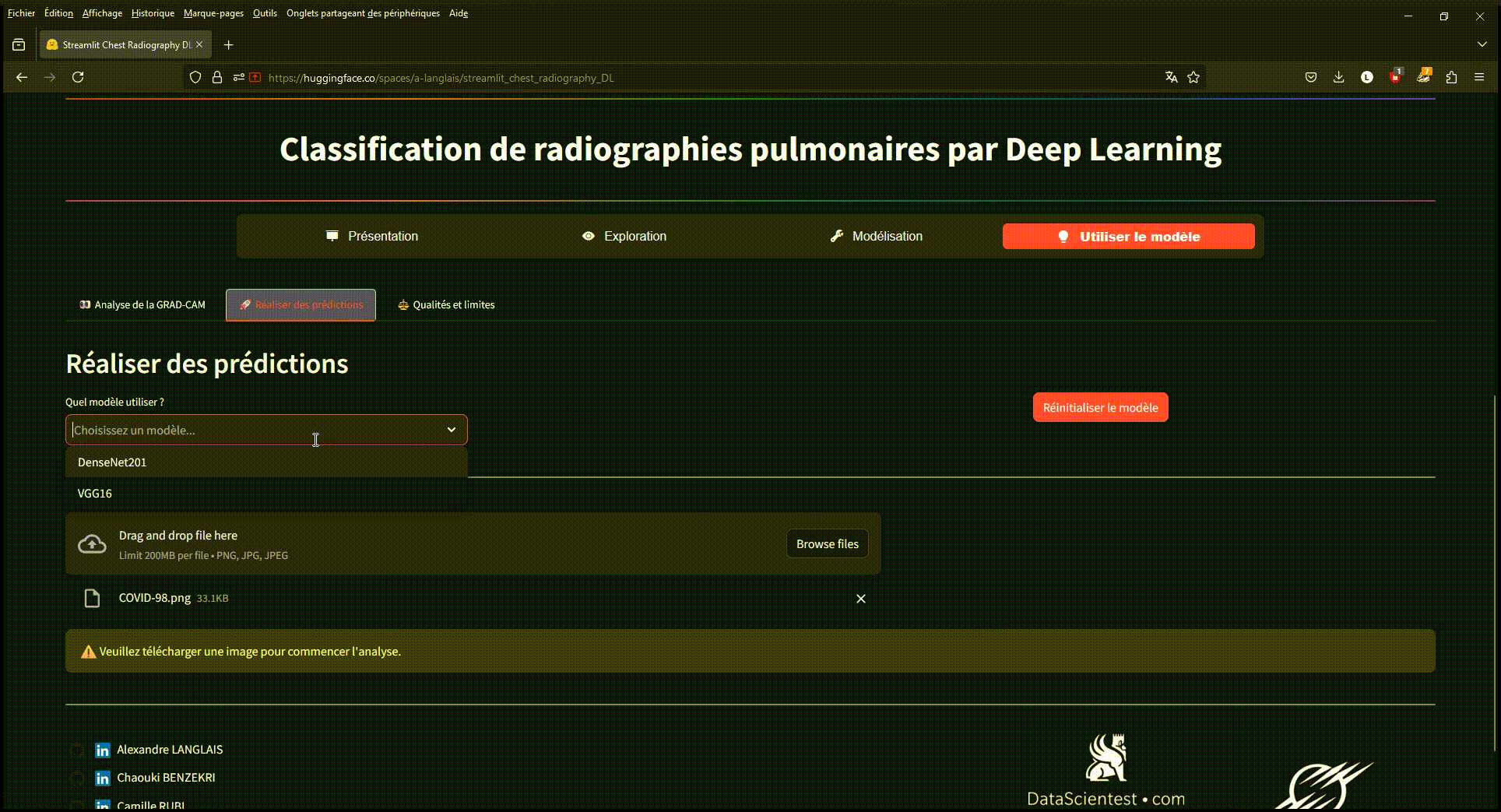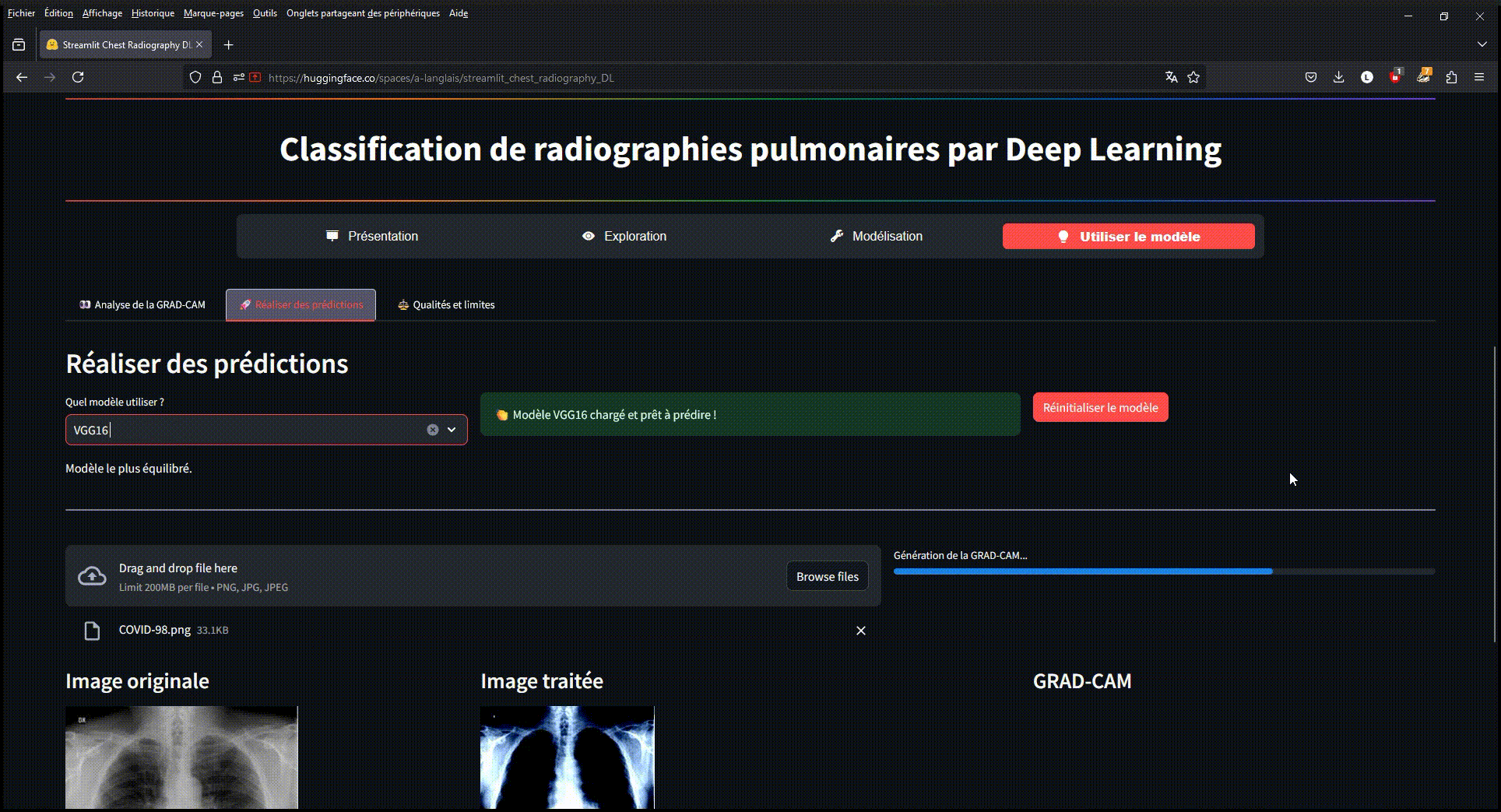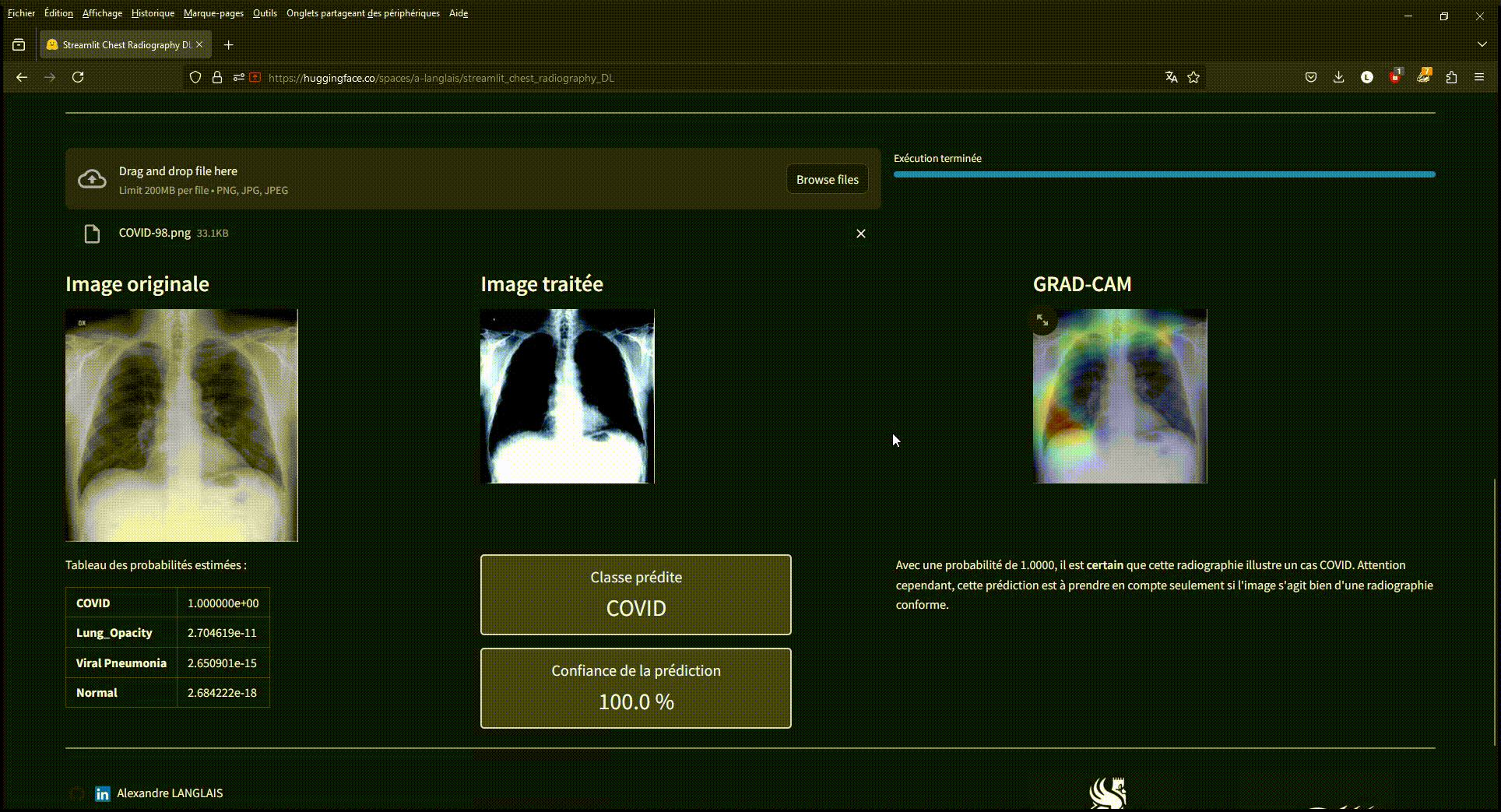
Exemple d'utilisation du modèle déployé sur une application Streamlit via Hugging-Face